Today on Product Saturday: Databricks introduces an open-source proposal for sharing corporate data, Datadog adds more bits to Bits AI, and the quote of the week.
Today: Anthropic's first Mythos-class AI model launch did not sit well with a lot of enterprise users, Oracle investors remain wary about its expansion plans, and the latest enterprise moves.
Today: Microsoft scrambles to minimize the fallout from a second batch of compromised open-source patches in a month, Apple teams up with Google for an expansion of its cloud security service, and the latest funding rounds in enterprise tech.
AI vendors promised indemnification against lawsuits. The details are messy.
Enterprise tech vendors promised customers that they will indemnify them from legal claims made against the output produced by generative AI tools. However, none of those companies want to talk about how it will actually work.
Amid all the excitement around generative AI in the enterprise, one nagging doubt has lingered: is this stuff legal?
Over the last six months, major enterprise tech vendors hoping to spur adoption of their expensive new tools have promised customers that they will indemnify them in any legal claims made against the output produced by those tools. Those vendors claim the new protections are in many ways an extension of the general terms of service that accompany the use of any enterprise tech product.
But generative AI is not an ordinary enterprise tech product.
Most generative AI foundation models were trained on a huge swath of content ingested from the internet, and a lot of that content could be protected by copyright law. Last week The New York Times sued Microsoft and OpenAI for using its content to train the groundbreaking ChatGPT service, a case that seems likely to test the boundaries of copyright law in the 21st century.
Perhaps fittingly, Microsoft was the first to promise customers in September that "if you are challenged on copyright grounds, we will assume responsibility for the potential legal risks involved," Vice Chair and President Brad Smith wrote in a blog post. Google Cloud followed shortly after, and around Thanksgiving OpenAI and AWS also announced plans to offer their enterprise customers some protection against generative AI-related lawsuits.
However, despite several attempts over the last few months, none of those companies have been willing to talk on the record about how AI indemnification policies will actually work. Enterprise customers using AI tools are unlikely to find themselves on the defense in the short term as plaintiffs focus on big fish like OpenAI and Microsoft, but the stakes could change quickly depending on the outcome of that case.
In order to be eligible for legal protection, customers have to use the vendor's controls and filters exactly as specified when generating output. But those vendors have said they will adjust those controls and filters over time as incidents like the discovery of child sex abuse material in the LAION-5B training dataset emerge, which demonstrated that there could be a significant amount of problematic material those existing filters are unable to detect.
And — as you might expect to see from some of the highest-paid legal teams on the planet — the terms of service that spell out these protections are filled with loopholes and ambiguous language that could shift the burden of complying with changing copyright laws to the customer.
"You're creating a legal standard that you want non-lawyers to know about and apply," said Kate Downing, an attorney who has written critically about GitHub's indemnification policies, in an interview. "You want a lawyer to review every single piece of generated output? That's impractical."
Stay inside the lines
Most enterprise generative AI services rely on a series of filters and controls to help their customers avoid using anything legally dubious in their output.
At Microsoft, "these (controls) build on and complement our work to protect digital safety, security, and privacy, based on a broad range of guardrails such as classifiers, metaprompts, content filtering, and operational monitoring and abuse detection, including that which potentially infringes third-party content," Smith said in the blog post.
Classifiers are "machine learning models that help to sort data into labeled classes or categories of information" and a metaprompt is a "program that serves to guide the system’s behavior. Parts of the metaprompt help align system behavior with Microsoft AI Principles and user expectations," according to a document produced by Microsoft to explain how generative AI technology was added to its Bing search engine.
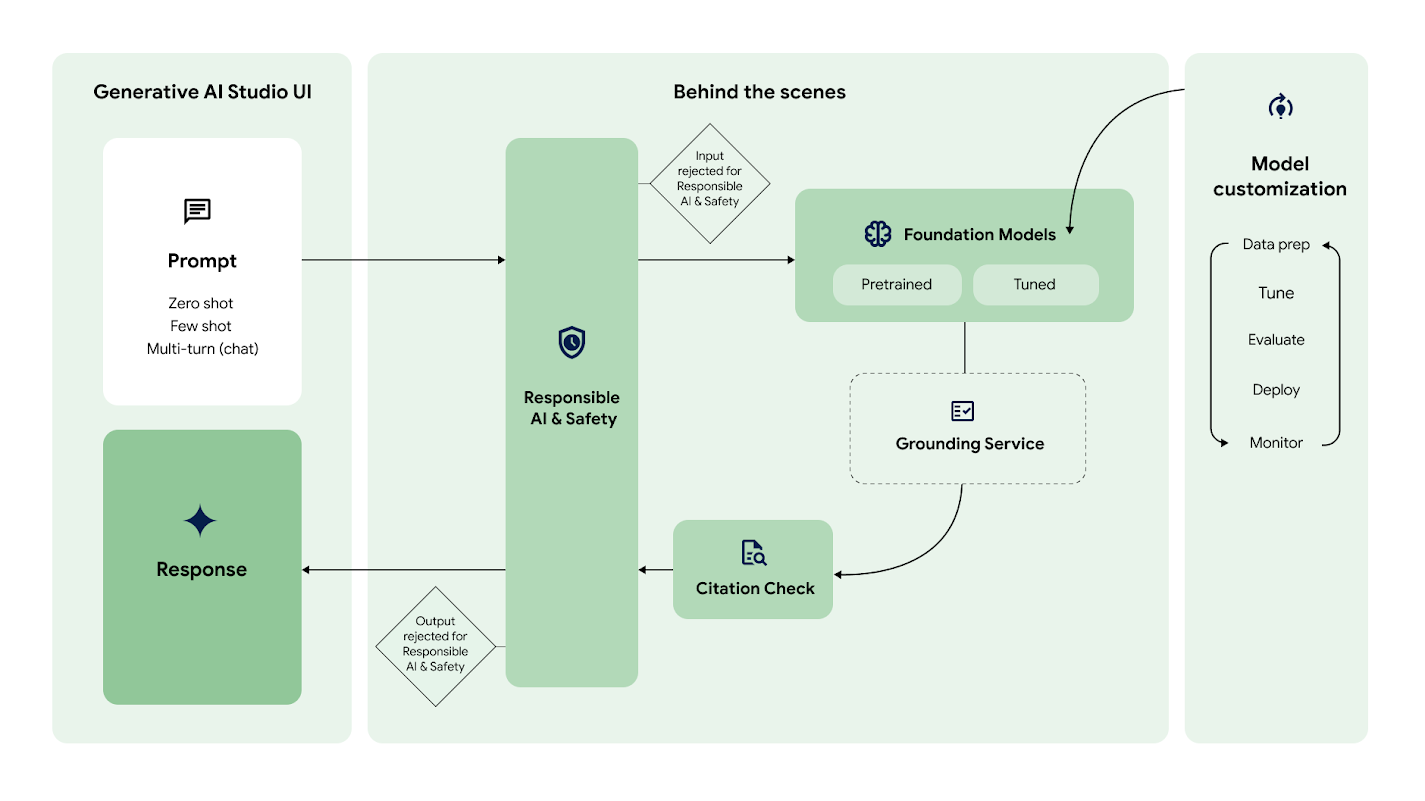
These guardrails serve as security guards at the gates of a large language model, as shown in this diagram produced by Google Cloud using slightly different terms.
Credit: Google
When a user enters a prompt into Vertex AI (Google's main generative AI service), the system checks that input against several different filters defined by the company's "Responsible AI and Safety" principles before that prompt ever goes to the foundational model chosen by the user. Similarly, another check is done after the foundation model generates its output but before the result reaches the end user.
In order to be eligible for AI indemnification, all the major vendors require that customers use their filters as designed. Based on several conversations with people working on these products who were unable to speak on the record, these filters aren't something you can accidentally uncheck in the settings menu; they claim customers would have to deliberately work around those guardrails to generate output based on copyright content.
However, "prompt engineering" is very much an emerging discipline and will likely grow more capable over time, according to those people. As a result, vendors need to adjust their filters over time to keep up with changing training data sets and skillful prompting to avoid generating output that runs afoul of the law, they said.
Still, very little transparency is provided into how those filters actually work, said Kate Kaye, deputy director at World Privacy Forum, which conducts research into AI governance. (Disclosure: I hired Kate to cover AI at Protocol Enterprise and think she's really smart.)
"They're kind of grading their own homework," Kaye said. However, it's likely that these companies have done some level of diligence.
"They're probably not going to say 'you're indemnified' if they haven't internally proven to themselves that they can know for sure that their software touched this copyrighted data," therefore allowing the companies to detect that material and filter it, she said.
What's in your data
However, it's clear from the LAION-5B investigation that some of these companies might not actually know what is in the training data they used to produce their models. Closed-source model providers, such as OpenAI, don't permit the kinds of investigations that Stanford researchers used to discover the CSAM references in that training data.
That is just straight-up bad lawyering, unless the goal was specifically to be ambiguous.
Perhaps that's why many of these indemnification clauses in the terms of service for products such as GitHub Copilot have loopholes large enough to drive a truck through, Downing said in a recent interview.
"With Copilot in particular, that's just bad drafting," she said. "That is just straight-up bad lawyering, unless the goal was specifically to be ambiguous."
For example, the specific terms of service that accompany Github Copilot and address indemnification specify "If your Agreement provides for the defense of third party claims, that provision will apply to your use of GitHub Copilot, including to the Suggestions you receive." However, the general terms of service that cover GitHub specifies that the company will only defend paying customers that have used a GitHub product "unmodified as provided by GitHub and not combined with anything else."
The entire point of using generative AI tools that make suggestions is to use those suggestions in combination with something else, such as your own custom code or your own marketing materials. While most generative AI lawsuits so far are directed at the model providers, "there is some uncertainty around whether the courts will accept that a model is a derivative work of the training data (and therefore, to the extent models are offered for physical distribution, making copies of the model also infringes the copyrights of the training data authors) or that all model output is a de facto infringement of the training data’s copyrights," Downing wrote in November.
If courts decide these issues in favor of the latter argument and output generated by GitHub Copilot is found to infringe copyright material, GitHub's general terms specify that it will terminate the customer's license or "modify or replace the Product with a functional equivalent." It's not at all clear whether the "Product" specified here extends to the suggestions generated by Copilot — as the specific terms of service appear to indicate — if those suggestions have been combined with custom code, Downing said.
And it's hard to see how GitHub would be able to find and replace all infringing code suggestions with non-infringing ones. So if GitHub settled a major copyright lawsuit on behalf of one of its customers under the indemnification policy, it could simply walk away from that customer and leave them to clean up the mess by rewriting a lot of code, and that is expensive.
Text-based generative AI suggestions are even trickier. For example, Google Cloud's terms of service specify that users of its generative AI tools won't receive indemnification if the customer "creates or uses such Generated Output that it knew or should have known was likely infringing." How can someone using Duet AI in Google Workspace to generate text for a marketing website know whether the output is "likely infringing" on someone else's copyright?
"Even very obvious kinds of forms of infringement, like things that are really obvious to lawyers are not at all obvious to non lawyers," Downing said.
This is very new territory for the legal system and it's far from clear where the law will settle a few years down the road.
"It's a very different kind of technology from any other software that's come before," Downing said. She pointed to examples like Salesforce and QuickBooks: When a user enters an input into that software, it's very easy to tell what the output should be, and if there is a dispute the code can be audited.
With generative AI, the user has no idea what's going to come out on the other end, and the vendor can't really tell you why that output emerged from that input, she said.
"It's an entirely different way of thinking about technology and technology systems that people were not used to, and I think that's part of what makes it really hard to understand the limitations of these technologies."
Tom Krazit has covered the technology industry for over 20 years, focused on enterprise technology during the rise of cloud computing over the last ten years at Gigaom, Structure and Protocol.
Today: Microsoft scrambles to minimize the fallout from a second batch of compromised open-source patches in a month, Apple teams up with Google for an expansion of its cloud security service, and the latest funding rounds in enterprise tech.
Today on Product Saturday: Microsoft unveils a new open-source project designed to get apps running on Microsoft Fabric, Workday launches a new agent-building tools and observability service, and the quote of the week.
Today: Microsoft's Omar Shahine thinks knowledge workers will soon delegate a lot of their busywork to its new personal assistant, Anthropic details how Claude is building Claude, and the latest enterprise moves.
Today: Snowflake hopes to make it easier for customers to share data and improve agent reliability, Microsoft jumps back in the AI model game, and the latest funding rounds in enterprise tech.