Today on Product Saturday: Fluidcloud releases what it calls a "large infrastructure model," Galileo releases an open-source way to manage agents, and the quote of the week.
Today: A series of Claude outages over the last few weeks illustrates that Anthropic's reliability challenge is not getting easier, Iran plans to target major enterprise tech installations in the Middle East, and the latest enterprise moves.
Today: Amazon shows how even the most advanced tech organizations need better guardrails in place during the AI coding boom, Anthropic sues the Department of Defense, and the latest funding rounds in enterprise tech.
As AI adoption surges, AI uptime remains a big problem
OpenAI and Anthropic both acknowledge they have a lot of work to do to improve the reliability of their services if they want to serve enterprise customers. But app developers also need to design their AI services with reliability in mind, which is hard when everyone is moving so fast.
Cloud computing would not have become a nearly $100 billion market without the development of an industry-wide culture focused on reliability. Asking CIOs to move their applications onto third-party servers was hard enough; convincing them that cloud providers could also run those applications better than the people that built them was just as tricky.
But, that's exactly what happened, and right now AI infrastructure providers like OpenAI and Anthropic find themselves in need of a similar breakthrough. A series of incidents at Anthropic in August and early September only highlighted what startups and application developers had been talking about for months: AI reliability falls short of what most businesses expect from their cloud providers, even after last week's massive AWS outage.
"It is what it is," Zencoder co-founder and CEO Andrew Filev told Runtime. "People are ready to live with it today because, one, they have no choice, and second, because of the productivity benefit" they get when everything works as it should, he said.
Engineering leaders at OpenAI and Anthropic are aware of the uptime issues, which — like most things involving massive distributed computing systems — stem from complex and fast-moving computer science and logistical problems. "Accelerated computing," as Nvidia CEO Jensen Huang likes to put it, is different from traditional computing, and not all of the lessons learned over the last 15 years of cloud computing apply to this new world.
However, the biggest issue might be that AI infrastructure teams are, as the old techie saying goes, building the plane while flying it. Even though most enterprises are still stuck in the airport security line when it comes to deploying AI in production, startups are racing to build so-called "AI native" versions of traditional enterprise software applications and internal teams are conducting lots of experiments that rely upon API calls to large-language models.
"The biggest kind of all-encompassing challenge here is the rate at which things are growing, not the aggregate scale, or anything fundamental that cannot be overcome with good engineering and good systems engineering," said Venkat Venkataramani, vice president of app infra at OpenAI.
Nine lives
Uptime is measured in "nines," as in, any provider that can't stay up more than 90% of the time over the last 90 days won't be in business very long. According to data from The Uptime Institute the Big Three cloud providers averaged around 99.97% uptime in 2024, which means they were only down for about two and a half hours over the course of the entire year.
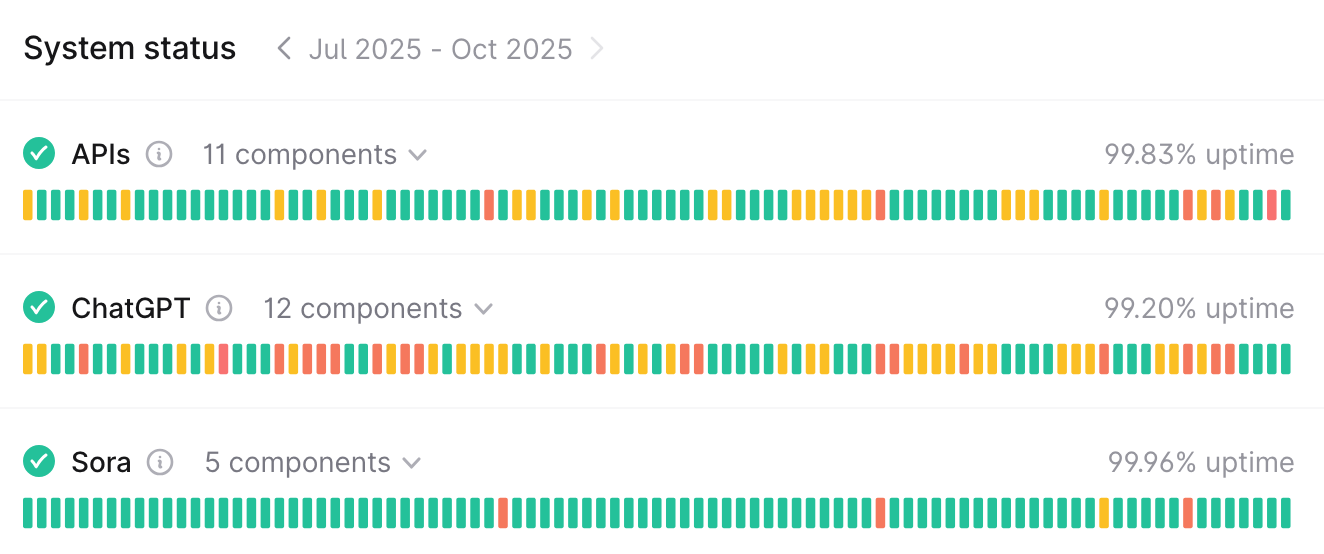
By contrast, over the last year OpenAI and Anthropic have both struggled to stay above 99% availability, which at that pace would mean their services would go dark for more than three and a half days over the course of a year. In practice, it means customers endure a lot of short but frustrating outages; during one week in early August OpenAI reported problems with ChatGPT every single business day.
OpenAI's ChatGPT service went through a rough stretch in August. (Runtime screenshot)
Anthropic went through its own bad stretch in August and into September, stumbling through a series of problems in August related to three infrastructure configuration issues and a hard outage on September 10th that took down several AI coding services that rely upon its APIs. Earlier this month it hired Rahul Patil, a veteran technology leader who has built infrastructure at Stripe, Oracle, and AWS, as its new chief technology officer, elevating former CTO and co-founder Sam McCandlish, who has more of a background in LLM development, to chief architect.
Both companies face a significant challenge when it comes to improving the reliability of their services, even before you take into account their plans for massive infrastructure expansion over the next several years. What we now consider traditional cloud infrastructure services were built around the scale-out principle of system design, which linked millions of relatively cheap servers built around Intel and AMD's x86 CPUs that could run basically any customer workload.
In this world, however, the GPU is the king. And not only do GPUs behave differently than CPUs, individual large-language models have to be deployed in very specific ways on custom hardware, said Todd Underwood, head of reliability at Anthropic.
"Each GPU chip is not like a separate computer that you can just scale across; they're custom integrated into huge chassis that have eight of these tied to one of these, connected to 16 of these … that is deployed in a way that is very different from how you would deploy, say, 40 or 200 or 200,000 CPU nodes," said Underwood, a veteran of Google's vaunted SRE (site reliability engineering) teams. Anthropic has also deployed its models across three different types of GPUs: Nvidia's (of course), AWS's Trainium and Inferentia chips, and Google's TPUs, which adds additional complexity.
GPUs are also more "flaky" than their CPU counterparts, Venkataramani said.
"There's typically less redundancy within the GPUs because of the complexity, like at the cache level; error reduction, and corrections and things like that that you just take for granted in CPUs are not always available," he said. And GPUs can also be easily overwhelmed during surges in demand because they run far less efficiently than traditional CPUs, said Alex Zenla, founder and CTO at Edera.
However, everyone interviewed for this story agreed that these reliability challenges are not insurmountable, and that clever engineering on both the AI model provider side as well as the application developer side will go a long way toward making AI inference as reliable as traditional compute workloads.
"We just have to invest a little bit more heavily into making sure we can very quickly and dynamically reroute when we're getting errors on certain endpoints," said Matan Grinberg, co-founder and CEO of AI coding tool Factory.
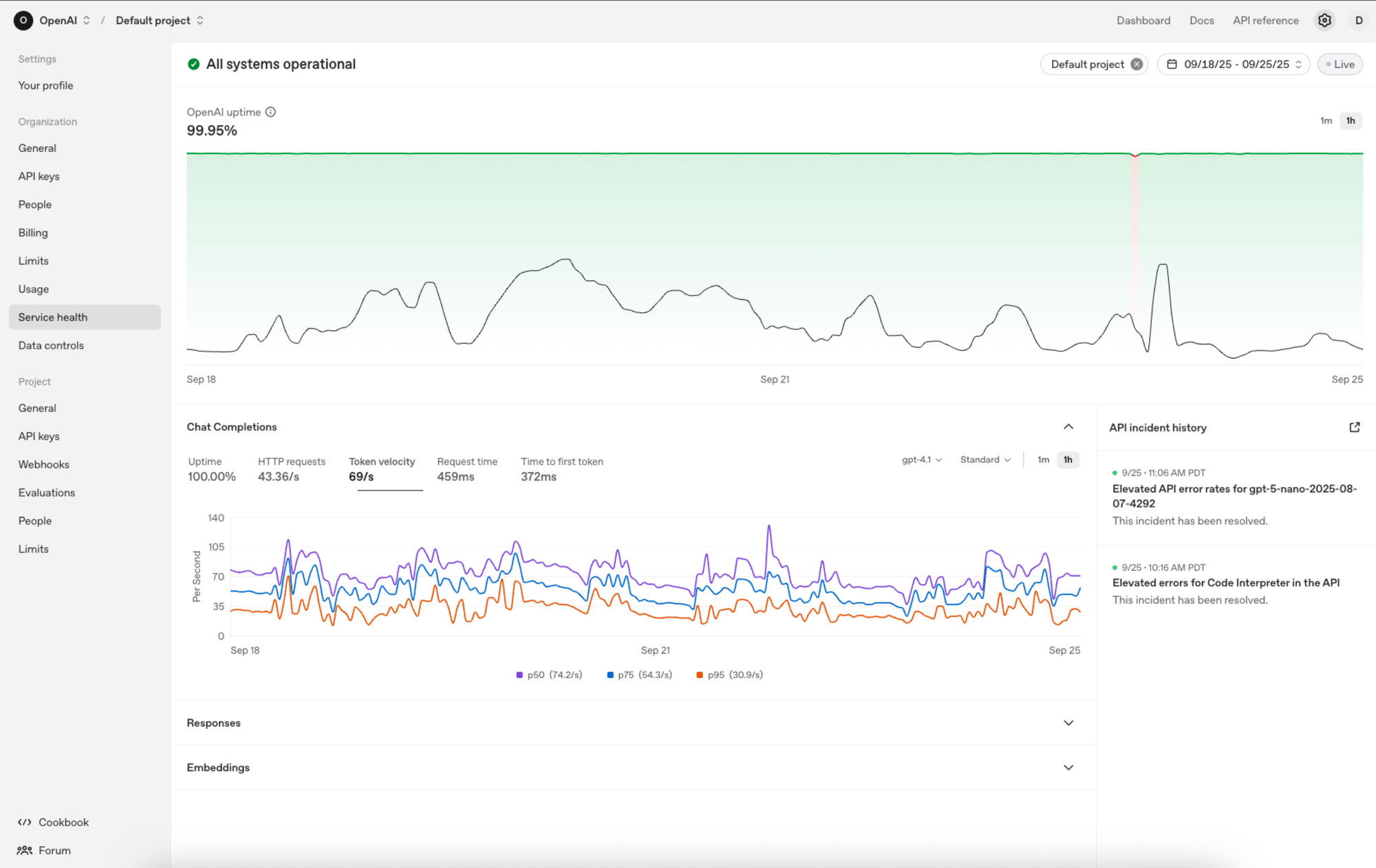
OpenAI recently introduced a new dashboard for customers that lets them track uptime and service disruptions without having to wait for details from the company, which could allow them to redirect their application toward a new model API when a problem is detected, Venkataramani said. A lot of app companies are already building features into their apps that let users switch between different models depending on the situation.
OpenAI's new customer dashboard for tracking model reliability. (Credit: OpenAI)
Anthropic is also working to improve the evaluations it uses to assess model performance, which it called out in its September postmortem as a problem that prevented the company from understanding how the model performance was degrading, Underwood said.
A lot of model evaluations were designed to be run during the model training process and can take hours to complete, which isn't that big a deal if you only need to do it once a day to track progress. But you're not going to get a great signal around ongoing model performance if the evaluation takes 16 hours to run, and that's an extremely expensive process, he said.
Edera, which is primarily known for its work on making traditional compute more secure and reliable with its approach toward container virtualization, is also looking at ways to apply that technology to GPU infrastructure, according to Zenla. "My perception is that if you increase the efficiency of the existing deployments, you might increase availability, because scaling events are easier for those providers," she said.
Right now generative AI applications and AI agents are still very new within the context of the enterprise, and aren't necessarily powering the same kinds of mission-critical services that cost those businesses money when a service like AWS goes down. But if companies actually do put AI agents at the heart of their customer-service applications or invoice-processing systems, reliability will become much more important.
"To some extent, even just maintaining a minimum level of availability in the middle of this growth is something," Underwood said. "But I think there's a bunch of work that we need to do that is just some, like, regular engineering work in this weird, technically complex context."
Tom Krazit has covered the technology industry for over 20 years, focused on enterprise technology during the rise of cloud computing over the last ten years at Gigaom, Structure and Protocol.
Today: A series of Claude outages over the last few weeks illustrates that Anthropic's reliability challenge is not getting easier, Iran plans to target major enterprise tech installations in the Middle East, and the latest enterprise moves.
Today: Amazon shows how even the most advanced tech organizations need better guardrails in place during the AI coding boom, Anthropic sues the Department of Defense, and the latest funding rounds in enterprise tech.
Today on Product Saturday: OpenAI rolls out two new models and a security agent, JavaScript developers have a new way to find npm packages, and the quote of the week.
Today: AWS and Google Cloud are pushing AI deeper into the healthcare industry, Anthropic is now officially considered a supply-chain risk by the U.S. government, and the latest enterprise moves.